Line identification I: Getting started
In this tutorial, we will learn how to use Spectuner to perform line identification.
[1]:
from pathlib import Path
import numpy as np
import spectuner
As an example, we will use the observed spectrum from a line survey towards Orion-KL in the frequency range of 67.0 - 93.6 GHz, conducted using GBT (Frayer et al. 2015). The data can be downloaded from VizieR at this link. The observed spectrum is provided in the file table2.dat in the downloaded data. Set fname_spec below to the path of table2.dat.
Secondly, we also require the CDMS spectroscopic database to run the code. Set fname_db below to path of the database file.
[2]:
fname_spec = "path/to/table2.dat"
fname_db = "path/to/the/cdms/database"
Preprocessing
To process an observed spectrum with Spectuner, ensure that the spectrum meet the following requirements:
The spectrum must be provided as a 2D array, where the first column represents the frequency in MHz and the second column represents the intensity in K.
The frequency values must be strictly increasing.
The baseline of the spectrum must be flat and zero.
It is highly recommended to correct the LSR velocity of the observed spectrum to avoid any confusion when settting the bound of the velocity offset.
[3]:
spec = np.loadtxt(fname_spec)
# Convert GHz to MHz
spec[:, 0] *= 1e3
# There is an issue in the data that the frequency is not strictly increasing
# We use the following trick to ensure that the frequency is strictly increasing
inds = np.append(0, np.where(np.diff(spec[:, 0]) > 0)[0] + 1)
spec = spec[inds]
# For speed reason, we only use a small window of the spectrum
lower = 89400
upper = 91400
spec = spec[(spec[:, 0] >= lower) & (spec[:, 0] < upper)]
Configuration
As a starting point, we may create a Config instance using load_default_config, and then make following settings.
Set the path to the spectroscopic database
Provide beam information and RMS noise for each spectral window
For single dish telescopes, set
beam_infoto the telescope diameter in meters.For interferometers, set
beam_infoto a tuple(BMAJ, BMIN), whereBMAJandBMINare the major and minor axis of the synthesis beam in degrees.
Adjust the
noise_factorto control peak detection sensitivity. Thenoise_factoris used to calculate the prominence threshold (prominence=noise*noise_factor), which determines how sensitive the peak detection is. The code uses find_peaks in Scipy to find the peaks.
[4]:
config = spectuner.load_default_config()
# Set the path to the spectroscopic database
config.set_fname_db(fname_db=fname_db)
# Set spectral windows.
config.append_spectral_window(
spec=spec,
beam_info=100., # Meter
noise=30e-3, # K
)
config.set_peak_manager(
noise_factor=4.
)
To check if our settings are expected, we can plot the observed spectrum and the identified peaks using SpectralPlot. The blue vertical lines in the figure below show peaks identified by the peak finder.
[5]:
peak_manager = spectuner.PeakManager.from_config(config)
plot = spectuner.SpectralPlot.from_config(config)
plot.vlines(peak_manager.freqs_peak, alpha=0.7)

Next, we can configure the chemical species for the line identification. In this example, we will specify C2H5CN and HCCCN as the target molecules. The code will automatically include their possible vibrational states and isotopologues. If you want to search all possible species, set species=None.
[6]:
config.set_ident_species(species=["C2H5CN", "HCCCN"])
The next step is make some settings related to the spectral line fitting:
Use the particle swarm optimization for line identification, i.e.
method="pso". This is a global optimization method with stochastic properties, meaning that running the algorithm multiple times may yield better results, which can be controlled usingn_trial. Start fromn_trial=1and increasen_trialto achieve more stable and consistent fits.Set appropriate bounds for the fitting parameters. When defining the parameter bounds, be mindful of if the parameter is in log-scale. To fix a parameter, a trick is to set the lower bound very close to (but not exactly equal to) its upper bound .
A portion of the code is parallelized using Python’s multiprocessing module. Set
n_processto specify how many CPU cores to use.
[7]:
# Set optimizer
config.set_optimizer(method="pso", n_trial=1)
# Set source size bound to 5 to 200 arcsec
config.set_param_info("theta", is_log=False, bound=(5., 200.))
# Set temperature bound to 10 to 400 K
config.set_param_info("T_ex", is_log=False, bound=(10., 400.))
# Set column density bound to 10^12 to 10^20 cm^-2
config.set_param_info("N_tot", is_log=True, bound=(12., 20.))
# Set velocity width bound to 1 to 25 km/s
config.set_param_info("delta_v", is_log=False, bound=(1., 25.))
# Set velcocity offset bound to -12 to 12 km/s
config.set_param_info("v_offset", is_log=False, bound=(-12., 12.))
# Set the number of processes
config.set_n_process(n_process=3)
Finally, as a good practice, we save the config to the same directory where the identification results will be stored. This helps keep the project organized and ensures that all relevant settings are preserved for future reference or reproducibility.
[8]:
# Set the directory to save results
# Change the directory for new runs; otherwise the code will overwrite the previous results.
result_dir = Path("results/")
result_dir.mkdir(exist_ok=True)
print(config)
{'obs_info': [{'spec': array([[ 8.9400202e+04, 1.0575000e-02],
[ 8.9400592e+04, -1.5704000e-02],
[ 8.9400983e+04, -4.9503000e-02],
...,
[ 9.1398901e+04, -4.8600000e-02],
[ 9.1399292e+04, 3.3773000e-02],
[ 9.1399682e+04, -3.0269000e-02]]),
'beam_info': 100.0,
'T_bg': 0.0,
'need_cmb': True,
'noise': 0.03}],
'fname_base': None,
'sl_model': {'fname_db': '/home/yqiu/repository/spectuner/tutorials/cdms_lite.db'},
'param_info': {'theta': {'is_shared': False,
'is_log': False,
'bound': (5.0, 200.0)},
'T_ex': {'is_shared': False,
'is_log': False,
'bound': (10.0, 400.0)},
'N_tot': {'is_shared': False,
'is_log': True,
'bound': (12.0, 20.0)},
'delta_v': {'is_shared': False,
'is_log': False,
'bound': (1.0, 25.0)},
'v_offset': {'is_shared': False,
'is_log': False,
'bound': (-12.0, 12.0)}},
'peak_manager': {'noise_factor': 4.0,
'rel_height': 0.25,
'freqs_exclude': None},
'n_process': 3,
'optimizer': {'method': 'pso', 'n_swarm': 28, 'n_trial': 1, 'n_draw': 50},
'identify': {'use_f_dice': True, 'criteria': {'score': 2.7, 't3_score': 0.8}},
'cube': {'species': None, 'need_spectra': True},
'inference': {'ckpt': None,
'device': 'cpu',
'batch_size': 64,
'num_workers': 2,
'max_diff': 10},
'species': {'species': ['C2H5CN', 'HCCCN'],
'combine_iso': False,
'combine_state': False,
'collect_iso': True,
'version_mode': 'default',
'include_hyper': False,
'exclude_list': None,
'rename_dict': None},
'modify': {'exclude_id_list': [],
'exclude_name_list': [],
'include_id_list': []}}
Running the algorithm
Now, we can run the line idetentification algorithm (Qiu et al. 2025), which has two phases:
The algorithm performs one-by-one fittings for each molecule in the user-defined list.
The algorithm combines the individual fitting results using a greedy method. It sorts the fitting results by their loss values. Starting with the best fit, and sequentially merges them.
The code below also saves the config as ‘config.pickle’ in the result directory
[9]:
%%time
spectuner.run_line_identification(config, result_dir)
Fitting: 100%|██████████████████████████████████████████████████████| 22/22 [00:54<00:00, 2.50s/it]
100%|███████████████████████████████████████████████████████████████| 21/21 [00:06<00:00, 3.30it/s]
Fitting: 0it [00:00, ?it/s]
CPU times: user 16.6 s, sys: 22 s, total: 38.6 s
Wall time: 1min 53s
Checking the results
We may use the ResultManager to check the results. For each phase, fitting results store the output of the optimization algorithm and identification results store the the scores related to the identification. ResultManager provides load_fitting_result and load_ident_result to load the results. If no peaks are found in the best-fitting model spectrum, the result will only
exist in the fitting results but not in the identification results.
[10]:
result_mgr = spectuner.ResultManager(result_dir)
result_mgr
[10]:
Fitting results (single):
- 0_C-13-H3C-13-H2CN;v=0;
- 10_HCC-13-C-13-N;v=0;
- 11_HCC-13-CN;v5=1;
- 12_HCC-13-CN;v6=1;
- 13_HCC-13-CN;v7=1;
- 14_HCC-13-CN;v7=3;
- 15_HCC-13-CN;v=0;
- 16_HCCC-13-N;v5=1;
- 17_HCCC-13-N;v=0;
- 18_HCCCN;v2=1;
- 19_HCCCN;v6=1;
- 1_C-13-H3CH2C-13-N;v=0;
- 20_HCCCN;v7=1;
- 21_HCCCN;v=0;
- 2_C-13-H3CH2CN;v=0;
- 3_C2H5CN;v12=1;
- 4_C2H5CN;v20=1;
- 5_C2H5CN;v=0;
- 6_CH3C-13-H2C-13-N;v=0;
- 7_CH3C-13-H2CN;v=0;
- 8_CH3CHDCN;v=0;
- 9_HC3N;v5=1,v7=1;
Identification results (single):
- 0_C-13-H3C-13-H2CN;v=0;
- 10_HCC-13-C-13-N;v=0;
- 11_HCC-13-CN;v5=1;
- 12_HCC-13-CN;v6=1;
- 13_HCC-13-CN;v7=1;
- 14_HCC-13-CN;v7=3;
- 15_HCC-13-CN;v=0;
- 17_HCCC-13-N;v=0;
- 18_HCCCN;v2=1;
- 19_HCCCN;v6=1;
- 20_HCCCN;v7=1;
- 21_HCCCN;v=0;
- 4_C2H5CN;v20=1;
- 5_C2H5CN;v=0;
- 6_CH3C-13-H2C-13-N;v=0;
- 8_CH3CHDCN;v=0;
- 9_HC3N;v5=1,v7=1;
Fitting results (combine):
- 0_C-13-H3C-13-H2CN;v=0;
- 10_HCC-13-C-13-N;v=0;
- 11_HCC-13-CN;v5=1;
- 12_HCC-13-CN;v6=1;
- 13_HCC-13-CN;v7=1;
- 14_HCC-13-CN;v7=3;
- 15_HCC-13-CN;v=0;
- 16_HCCC-13-N;v5=1;
- 17_HCCC-13-N;v=0;
- 18_HCCCN;v2=1;
- 19_HCCCN;v6=1;
- 1_C-13-H3CH2C-13-N;v=0;
- 20_HCCCN;v7=1;
- 21_HCCCN;v=0;
- 2_C-13-H3CH2CN;v=0;
- 3_C2H5CN;v12=1;
- 4_C2H5CN;v20=1;
- 6_CH3C-13-H2C-13-N;v=0;
- 7_CH3C-13-H2CN;v=0;
- 8_CH3CHDCN;v=0;
- 9_HC3N;v5=1,v7=1;
- combine
Identification results (combine):
- 0_C-13-H3C-13-H2CN;v=0;
- 10_HCC-13-C-13-N;v=0;
- 11_HCC-13-CN;v5=1;
- 12_HCC-13-CN;v6=1;
- 13_HCC-13-CN;v7=1;
- 14_HCC-13-CN;v7=3;
- 15_HCC-13-CN;v=0;
- 17_HCCC-13-N;v=0;
- 18_HCCCN;v2=1;
- 19_HCCCN;v6=1;
- 20_HCCCN;v7=1;
- 21_HCCCN;v=0;
- 4_C2H5CN;v20=1;
- 6_CH3C-13-H2C-13-N;v=0;
- 8_CH3CHDCN;v=0;
- 9_HC3N;v5=1,v7=1;
- combine
Fitting results (modified):
- combine
Identification results (modified):
- combine
We are most interested in the final result of the combining phase, which summarizes the molecules that have been identified with more than three matching spectral peaks.
The result can be loaded using code below. We may use ResultManager.derive_df_mol to check the parameters and scores for each molecule, which returns a Pandas DataFrame. Here is the meaning of the columns:
‘theta’: Source size in arcsec.
‘T_ex’: Excitation temperature in K.
‘N_tot’: Total column density in cm^-2.
‘delta_v’: Line width in km/s.
‘v_offset’: Velocity offset in km/s.
‘loss’: Total peak matching fitness. This is proportional to the sum of the intensity of all matched peaks.
‘score’: Total peak matching score. This is roughly equal to the sum of the noramlized score of all peaks.
‘num_tp’: Number of matched peaks.
‘num_tp_i’: Number of matched peaks contributed from only one molecule.
‘num_fp’: Number of peaks found in the model spectrum but missed in the observed spectrum.
‘tx_score’: The x-th largest value among all socres of matched peaks. This score ranges from 0 to 1, with values closer to 1 being better.
[11]:
res = result_mgr.load_ident_result("combine", "combine")
res.derive_df_mol()
[11]:
| id | name | master_name | theta | T_ex | N_tot | delta_v | v_offset | loss | score | num_tp | num_tp_i | num_fp | t1_score | t2_score | t3_score | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 5 | C2H5CN;v=0; | C2H5CN;v=0; | 137.527725 | 348.872803 | 7.725220e+15 | 7.160223 | 5.442149 | -10.038683 | 7.255817 | 12 | 12 | 0 | 0.957959 | 0.955638 | 0.884301 |
We may use SpectralPlot to visualize the combined result.
[12]:
plot = spectuner.SpectralPlot.from_config(config)
plot.plot_ident_result(res, kwargs_spec={"color": "r"})
plot.plot_unknown_lines(res)
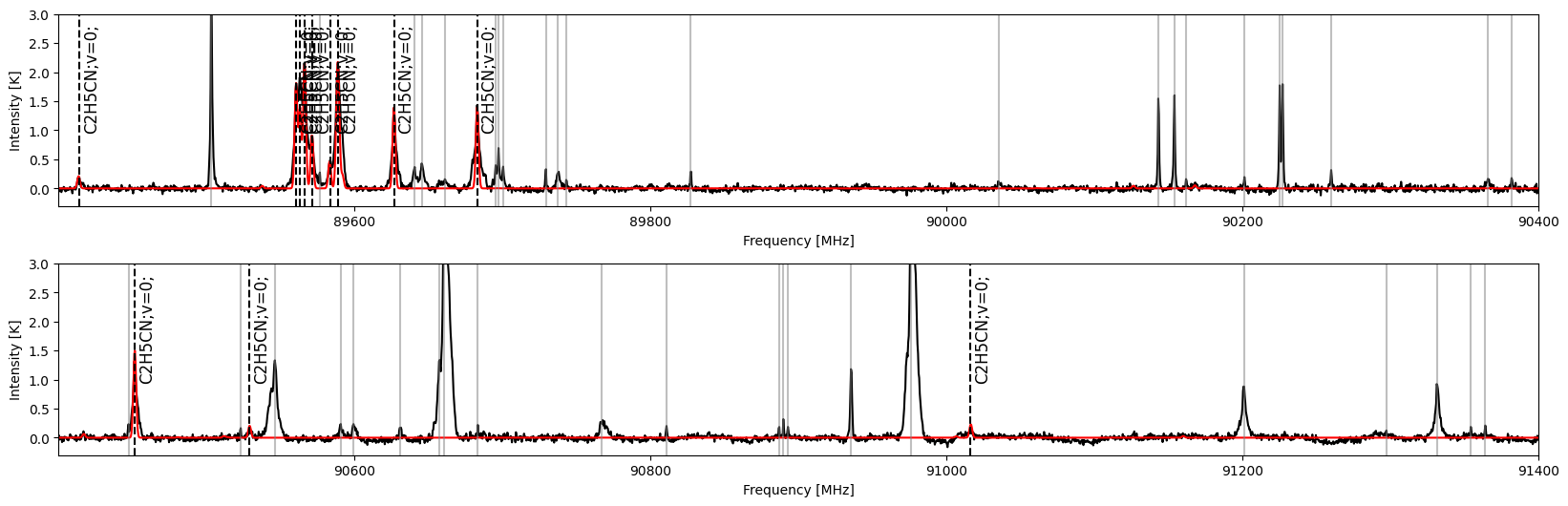
The combined result excludes molecules which have one or two matched peaks. Use the code below to show a summary of such molecules.
[13]:
df_cand = result_mgr.derive_df_mol_master()
df_cand
[13]:
| id | master_name | loss | score | num_tp | num_tp_i | num_fp | t1_score | t2_score | t3_score | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 20 | HCCCN;v7=1; | -1.576792 | 1.906376 | 2 | 2 | 0 | 0.987747 | 0.918629 | 0.0 |
| 1 | 4 | C2H5CN;v20=1; | -0.242952 | -0.779588 | 3 | 3 | 5 | 0.760013 | 0.485397 | 0.0 |
| 2 | 0 | C-13-H3C-13-H2CN;v=0; | -0.139508 | 0.999432 | 1 | 1 | 1 | 0.999992 | 0.000000 | 0.0 |
| 3 | 12 | HCC-13-CN;v6=1; | -0.132423 | 0.813306 | 1 | 1 | 1 | 0.999987 | 0.000000 | 0.0 |
| 4 | 10 | HCC-13-C-13-N;v=0; | -0.146281 | 0.999978 | 1 | 1 | 0 | 0.999978 | 0.000000 | 0.0 |
| 5 | 8 | CH3CHDCN;v=0; | -0.236441 | 0.999940 | 1 | 1 | 0 | 0.999940 | 0.000000 | 0.0 |
| 6 | 13 | HCC-13-CN;v7=1; | -0.775333 | 0.124308 | 1 | 1 | 1 | 0.999204 | 0.000000 | 0.0 |
| 7 | 21 | HCCCN;v=0; | -7.214780 | 0.997347 | 1 | 1 | 0 | 0.997347 | 0.000000 | 0.0 |
| 8 | 18 | HCCCN;v2=1; | -1.167083 | 0.981574 | 1 | 1 | 0 | 0.981574 | 0.000000 | 0.0 |
| 9 | 15 | HCC-13-CN;v=0; | -0.193587 | 0.972850 | 1 | 1 | 0 | 0.972850 | 0.000000 | 0.0 |
| 10 | 19 | HCCCN;v6=1; | -0.268051 | 0.122558 | 1 | 1 | 1 | 0.971364 | 0.000000 | 0.0 |
| 11 | 14 | HCC-13-CN;v7=3; | -0.090292 | 0.962406 | 1 | 1 | 0 | 0.962406 | 0.000000 | 0.0 |
| 12 | 17 | HCCC-13-N;v=0; | -0.202612 | 0.958352 | 1 | 1 | 0 | 0.958352 | 0.000000 | 0.0 |
| 13 | 11 | HCC-13-CN;v5=1; | -0.149608 | 0.523247 | 1 | 1 | 1 | 0.957195 | 0.000000 | 0.0 |
| 14 | 9 | HC3N;v5=1,v7=1; | -0.012584 | 0.134127 | 1 | 1 | 0 | 0.134127 | 0.000000 | 0.0 |
| 15 | 6 | CH3C-13-H2C-13-N;v=0; | 0.000000 | 0.000000 | 0 | 0 | 1 | 0.000000 | 0.000000 | 0.0 |
An additional way to check the candidate results is to query an unidentified line. The code below check if there are candidates for the line at 91200 MHz.
[14]:
result_mgr.query_line(91200)
[14]:
['19_HCCCN;v6=1;', '20_HCCCN;v7=1;']
We can access and visualize the identitfication result of HCCCN, v7=1 (id=20) using the following code.
[15]:
res_cand = result_mgr.load_ident_result("combine", "20_HCCCN;v7=1;")
res_cand.derive_df_mol()
[15]:
| id | name | master_name | theta | T_ex | N_tot | delta_v | v_offset | loss | score | num_tp | num_tp_i | num_fp | t1_score | t2_score | t3_score | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 20 | HCCCN;v7=1; | HCCCN;v7=1; | 194.738998 | 139.025925 | 9.670201e+14 | 7.817645 | 5.325488 | -1.576792 | 1.906376 | 2 | 2 | 0 | 0.987747 | 0.918629 | 0.0 |
[16]:
plot = spectuner.SpectralPlot.from_config(config)
plot.plot_ident_result(res, show_lines=False, kwargs_spec={"color": "r"})
plot.plot_ident_result(res_cand, kwargs_spec={"color": "b"})

We are able to modify the combined result. The code below adds HCCCN, v7=1 (id=20) to the combined result. For applications using Python scripts instead of notebooks, we may use load_config to load the configuration file saved before.
[17]:
config = spectuner.load_config(result_dir/"config.pickle")
config.set_modificaiton_lists(include_id_list=[20])
spectuner.modify(config, result_dir)
If this has been done sucessfully, we can use the following code to access and visualize the modified result.
[18]:
# To access the modified result, we need to create a new ResultManager object.
result_mgr = spectuner.ResultManager(result_dir)
res_modify = result_mgr.load_ident_result("modified", "combine")
plot = spectuner.SpectralPlot.from_config(config)
plot.plot_ident_result(res_modify, kwargs_spec={"color": "r"})

Exercises
For observations made with single-dish telescopes, the RMS noise is not uniform across the entire spectrum. To account for this variation, try dividing the spectrum into multiple spectral windows and assign appropriate RMS noise values to each window before performing the identification.
References
Frayer, D. T., Maddalena, R. J., Meijer, M., et al. (2015), The GBT 67-93.6 GHz Spectral Line Survey of Orion-KL, The Astronomical Journal, 149, 162.
Qiu, Y., Zhang, T., Möller, T., et al. (2025), Spectuner: A Framework for Automated Line Identification of Interstellar Molecules, The Astrophysical Journal Supplement Series, 277, 21.